Hi, I’m Michael Ryan and I’m a PhD student and Knight-Hennessy scholar studying Artificial Intelligence at Stanford University. I’m fortunate to be advised by Diyi Yang and Percy Liang! I work on Open-Source, Human-Centered AI. I’m a core contributor to StanfordNLP/DSPy – the library for programming not prompting LLMs. I am also contributing to the Open Development of LLMs through the Marin Project!
My research interest is Open Source, Human-Centered AI in two directions: Making AI better for various cultures, languages, and individuals [1] [2] [3]. And leveraging humans for system design/feedback to make better AI systems [4] [5]. Previously I was an undergraduate in Wei Xu’s NLP X Lab at Georgia Tech and a research intern at Snowflake.
Have a look at my CV, or if you’re in a hurry, check out my resume!
- Human-Centered LLM Development
- AI Personalization
- Compound LM Systems
PhD in Computer Science, 202X
Stanford University
MS in Computer Science, 2025
Stanford University
BSc in Computer Science (Intelligence & Systems/Architecture), 2023
Georgia Institute of Technology
Selected Research
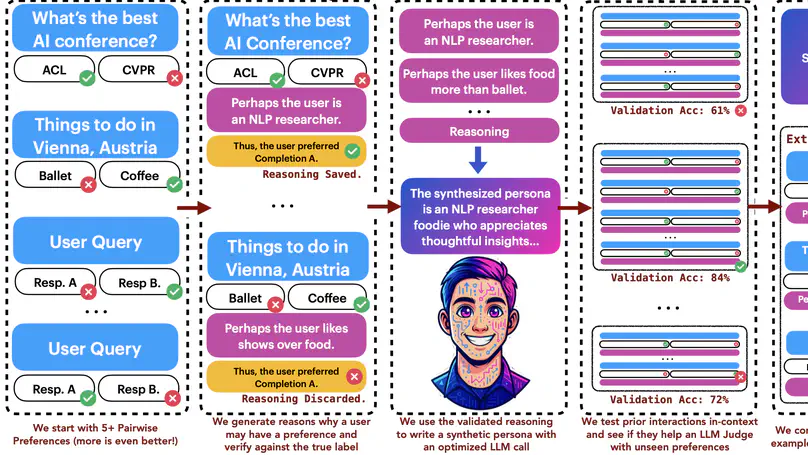
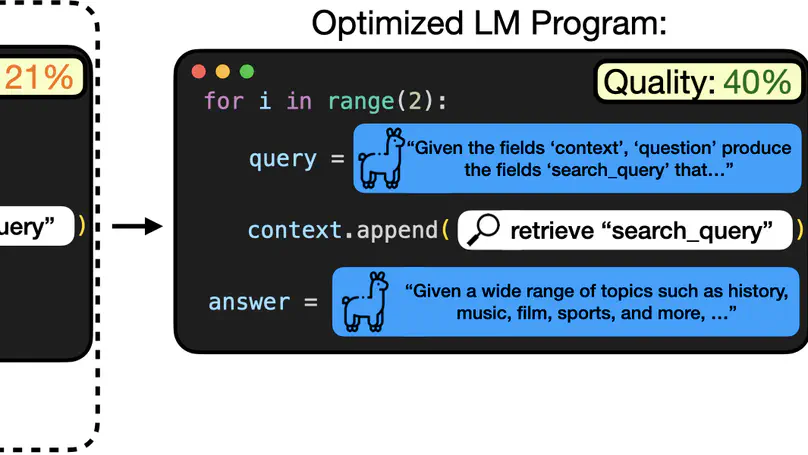
Teaching
Work Experience
- Designed and programmed static analysis tool in C++ for identifying security vulnerabilities throughout Windows OS.
- Refactored existing codebase from .NET Framework to .NET Core.
- Ported server-specific architecture to serverless functional units using Azure Durable Functions.
- Implemented end-to-end testing in GoLang for bike, scooter, and moped rentals by building a simulated 3rd party CRUD API.
Projects