Michael Ryan
Michael Ryan
Home
Research
Teaching
Work
Projects
Contact
1
SynthesizeMe! Inducing Persona-Guided Prompts for Personalized Reward Models in LLMs
Recent calls for pluralistic alignment of Large Language Models (LLMs) encourage adapting models to diverse user preferences. However, most prior work on personalized reward models heavily rely on additional identity information, such as demographic details or a predefined set of preference categories. To this end, we introduce SynthesizeMe, an approach to inducing synthetic user personas from user interactions for personalized reward modeling. SynthesizeMe first generates and verifies reasoning to explain user preferences, then induces synthetic user personas from that reasoning, and finally filters to informative prior user interactions in order to build personalized prompts for a particular user. We show that using SynthesizeMe induced prompts improves personalized LLM-as-a-judge accuracy by 4.4% on Chatbot Arena. Combining SynthesizeMe derived prompts with a reward model achieves top performance on PersonalRewardBench a new curation of user-stratified interactions with chatbots collected from 854 users of Chatbot Arena and PRISM.
Michael J. Ryan
,
Omar Shaikh
,
Aditri Bhagirath
,
Daniel Frees
,
William Held
,
Diyi Yang
PDF
Cite
Code
Dataset
Poster
Slides
Mind the Gap: Static and Interactive Evaluations of Large Audio Models
As AI chatbots become ubiquitous, voice interaction presents a compelling way to enable rapid, high-bandwidth communication for both semantic and social signals. This has driven research into Large Audio Models (LAMs) to power voice-native experiences. However, aligning LAM development with user goals requires a clear understanding of user needs and preferences to establish reliable progress metrics. This study addresses these challenges by introducing an interactive approach to evaluate LAMs and collecting 7,500 LAM interactions from 484 participants. Through topic modeling of user queries, we identify primary use cases for audio interfaces. We then analyze user preference rankings and qualitative feedback to determine which models best align with user needs. Finally, we evaluate how static benchmarks predict interactive performance - our analysis reveals no individual benchmark strongly correlates with interactive results (𝜏 ≤ 0.33 for all benchmarks). While combining multiple coarse-grained features yields modest predictive power (R2=0.30), only two out of twenty datasets on spoken question answering and age prediction show significantly positive correlations. This suggests a clear need to develop LAM evaluations that better correlate with user preferences.
Ella Li
,
William Held
,
Michael J. Ryan
,
Kunat Pipatanakul
,
Potsawee Manakul
,
Hao Zhu
,
Diyi Yang
PDF
Cite
Code
Source Document
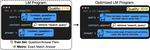
Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs
We present MIPROv2, a language model program optimizer which improves both prompts and fewshot demonstrations for multistage language model programs. Our strategies include (i) program- and data-aware techniques for proposing effective instructions, (ii) a stochastic mini-batch evaluation function for learning a surrogate model of our objective, and (iii) a meta-optimization procedure in which we refine how LMs construct proposals over time. MIPRO outperforms baseline optimizers on five of seven diverse multi-stage LM programs using a best-in-class open-source model (Llama-3-8B), by as high as 13% accuracy.
Krista Opsahl-Ong*
,
Michael J. Ryan*
,
Josh Purtell
,
David Broman
,
Christopher Potts
,
Matei Zaharia
,
Omar Khattab
PDF
Cite
Code
Dataset
Slides
Video
DOI
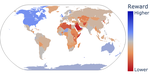
Unintended Impacts of LLM Alignment on Global Representation
We explore how alignment impacts performance along three axes of global representation, English dialects, multilingualism, and opinions from and about countries worldwide. Our results show that current alignment procedures create disparities between English dialects and global opinions. We find alignment improves capabilities in several languages. We conclude by discussing design decisions that led to these unintended impacts and recommendations for more equitable preference tuning.
Michael J. Ryan
,
William Held
,
Diyi Yang
PDF
Cite
Code
Dataset
Poster
Slides
Video
DOI
Revisiting non-English Text Simplification: A Unified Multilingual Benchmark
We release the MultiSim benchmark, a collection of 27 resources in 12 distinct languages containing over 1.7 million complex-simple sentence pairs. This benchmark will encourage research in developing more effective multilingual text simplification models and evaluation metrics. Our experiments using MultiSim with pre-trained multilingual language models reveal exciting performance improvements from multilingual training in non-English settings.
Michael J. Ryan
,
Tarek Naous
,
Wei Xu
PDF
Cite
Code
Dataset
Poster
Slides
Video
DOI
Towards Massively Multi-domain Multilingual Readability Assessment
We present ReadMe++, a massively multi-domain multilingual dataset for automatic readability assessment. Prior work on readability assessment has been mostly restricted to the English language and one or two text domains. Additionally, the readability levels of sentences used in many previous datasets are assumed on the document-level other than sentence-level, which raises doubt about the quality of previous evaluations. We address those gaps in the literature by providing an annotated dataset of 9,757 sentences in Arabic, English, Hindi, French, and Russian collected from 112 different sources.
Tarek Naous
,
Michael J. Ryan
,
Anton Lavrouk
,
Mohit Chandra
,
Wei Xu
PDF
Cite
Dataset
Cloud Computed Machine Learning Based Real-Time Litter Detection using Micro-UAV Surveillance
Litter can remain undetected and uncollected for extended periods of time, leading to detrimental consequences on the environment. The use of drones to detect this litter marks an important step towards solving this problem. We test five different computer vision algorithms for litter detection using drone surveillance and show a bagging ensemble of these methods to have the highest performance.
Ashley Chung
,
Sean Kim
,
Ethan Kwok
,
Michael J. Ryan
,
Erika Tan
,
Ryan Gamadia
PDF
Cite
Code
Video
DOI
Cite
×